 Abhishek Jha
Abhishek Jha Post-doctoral researcher, Goncalves Lab,
VIB-NERF
Katholieke Universiteit Leuven
Email: abhishek [dot] jha [at] kuleuven.be
Bio
I am a Postdoctoral researcher at NERF, VIB-KU Leuven, advised by Dr. Pedro J. Gonçalves. I completed my PhD as an ELLIS doctoral student at KU Leuven, supervised by Prof. Tinne Tuytelaars, and co-supervised by Dr. Yuki Asano. My doctoral research focused on representation learning, particularly in developing robust and interpretable representations.
Prior to joining the doctoral school I have spent a brief time visiting IISc Bangalore as a Project Assistant at MALL Lab, working with Dr. Partha Pratim Talukdar, Dr. Anirban Chokraborty and Dr. Anand Mishra on a project on Weakly supervised video understanding using Knowledge Graphs (KG).
I completed my Masters (MS) at IIIT Hyderabad, where I was jointly advised by Prof. C. V. Jawahar and Prof. Vinay P. Namboodiri at Center for Visual Information Technology. My masters research was focused on solving Visual Speech Recognition (VSR) which lies at the intersection of multiple modalities like videos (speech videos) audios (speech audio) and texts (Natural language). I have also worked in the space of Image stylization for enabling cross-modal transfer of style.
Updates
| [Oct 2025] | I am joining Gonçalves lab, VIB-NERF, KU Leuven, as a Postdoctoral researcher. |
| [Jul 2025] | [Oral] Accepted: Our paper HierVision accepted in Beyond Euclidean Workshop, at ICCV 2025. |
| [Mar 2025] | Successfully defended my PhD thesis at KU Leuven, titled: Understanding and Transferring the Learning Dynamics of Visual Representations in the Absence of Labels. |
| [Sep 2024] | Accepted: “Analysis of Spatial augmentation in Self-supervised models in the purview of training and test distributions” accepted at ECCV 2024 Workshop on Out-of-distribution generalization in computer vision (OOD-CV). |
| [Feb 2024] | Preprint: The Common Stability Mechanism behind most Self-Supervised Learning Approaches |
| [Oct 2023] | I will be doing an ELLIS research visit at University of Amsterdam, Netherlands, under the supervision of Dr. Yuki Asano. |
| [Jul 2023] | Attending: ICVSS 2023, Sicily, Italy. I will also be presenting a poster on Exploring the stability of Self-Supervised Representations. |
| [Oct 2022] | Accepted: Our paper “SimGlim: Simplifying glimpse based active visual reconstruction” in WACV 2023. |
| [Sep 2022] | Accepted: Our paper Barlow constrained optimization for Visual Question Answering, in WACV 2023. |
| [Aug 2022] | I will be attending ELLIS Doctoral symposium 2022 in Alicante, Spain. |
| [Aug 2021] | Accepted: Our paper “Glimpse-Attend-and-Explore: Self-Attention for Active Visual Exploration” in ICCV 2021. |
| [Jan 2021] | Presented a poster on “ Transferability of Self-Supervised Representations” in Mediterranean Machine Learning summer school 2021. |
Publications
Full list of publications can be found on Google Scholar.
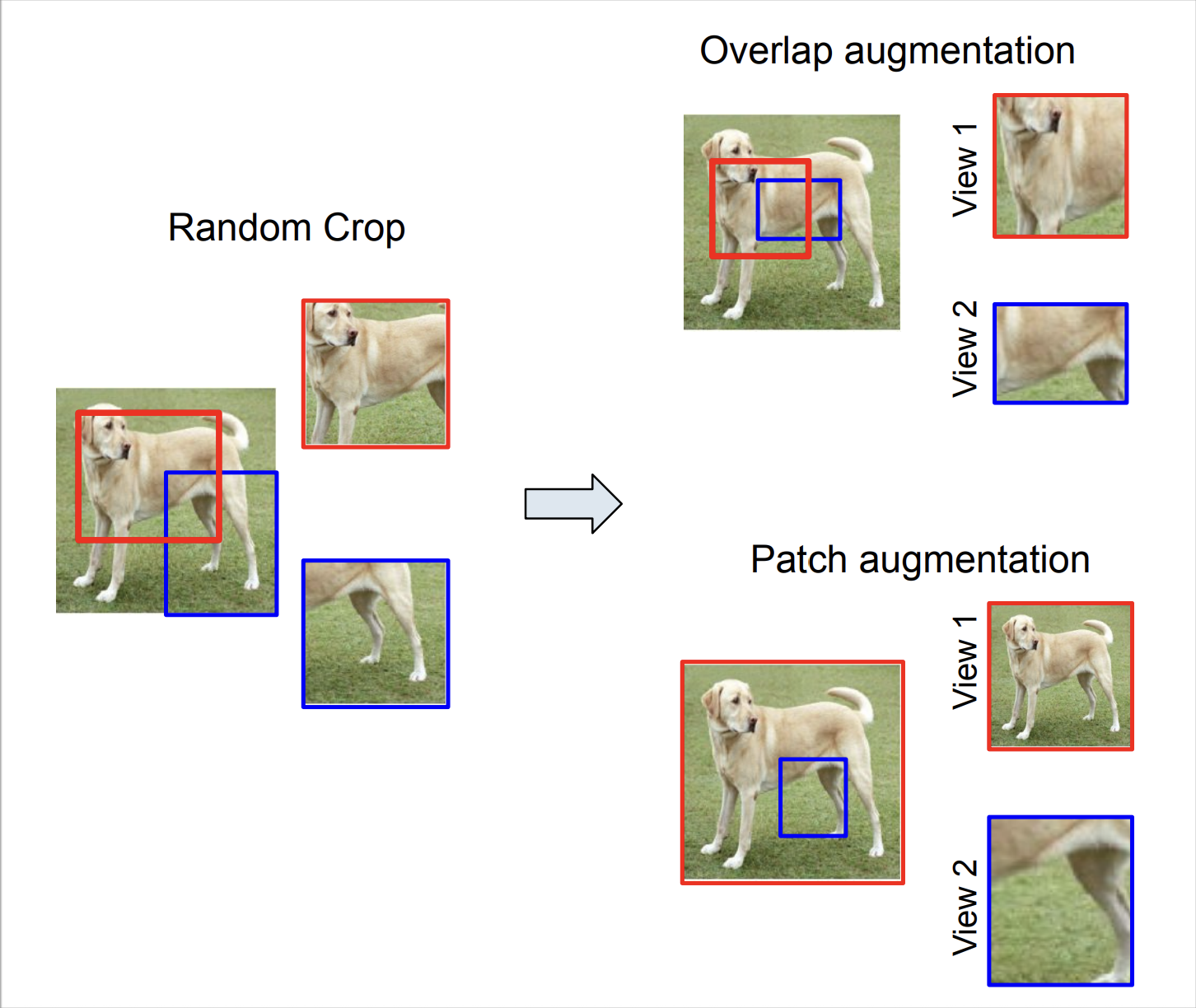 |
Analysis of Spatial augmentation in Self-supervised models in the purview of training and test distributions Abstract
In this paper, we present an empirical study of typical spatial augmentation techniques used in self-supervised representation learning methods (both contrastive and non-contrastive), namely random crop and cutout. Our contributions are: (a) we dissociate random cropping into two separate augmentations, overlap and patch, and provide a detailed analysis on the effect of area of overlap and patch size to the accuracy on down stream tasks. (b) We offer an insight into why cutout augmentation does not learn good representation, as reported in earlier literature. Finally, based on these analysis, (c) we propose a distance-based margin to the invariance loss for learning scene-centric representations for the downstream task on object-centric distribution, showing that as simple as a margin proportional to the pixel distance between the two spatial views in the scence-centric images can improve the learned representation. Our study furthers the understanding of the spatial augmentations, and the effect of the domain-gap between the training augmentations and the test distribution. |
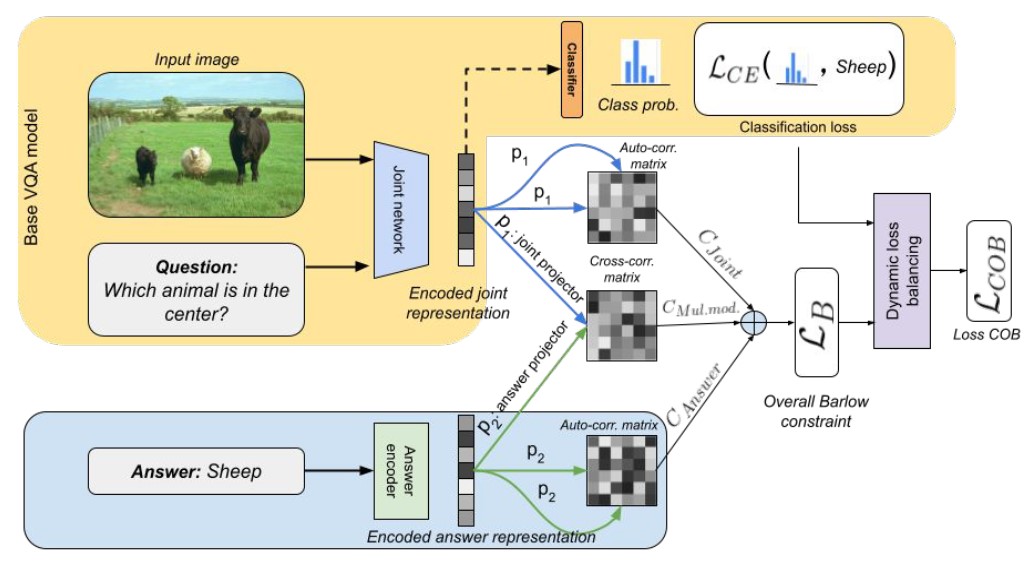 |
Barlow constrained Visual Question Answering Abstract
Visual question answering is a vision-and-language multimodal task, that aims at predicting answers given samples from the question and image modalities. Most recent methods focus on learning a good joint embedding space of images and questions, either by improving the interaction between these two modalities, or by making it a more discriminant space. However, how informative this joint space is, has not been well explored. In this paper, we propose a novel regularization for VQA models, Constrained Optimization using Barlow's theory (COB), that improves the information content of the joint space by minimizing the redundancy. It reduces the correlation between the learned feature components and thereby disentangles semantic concepts. Our model also aligns the joint space with the answer embedding space, where we consider the answer and image+question as two different `views' of what in essence is the same semantic information. We propose a constrained optimization policy to balance the categorical and redundancy minimization forces. When built on the state-of-the-art GGE model, the resulting model improves VQA accuracy by 1.4% and 4% on the VQA-CP v2 and VQA v2 datasets respectively. The model also exhibits better interpretability. |
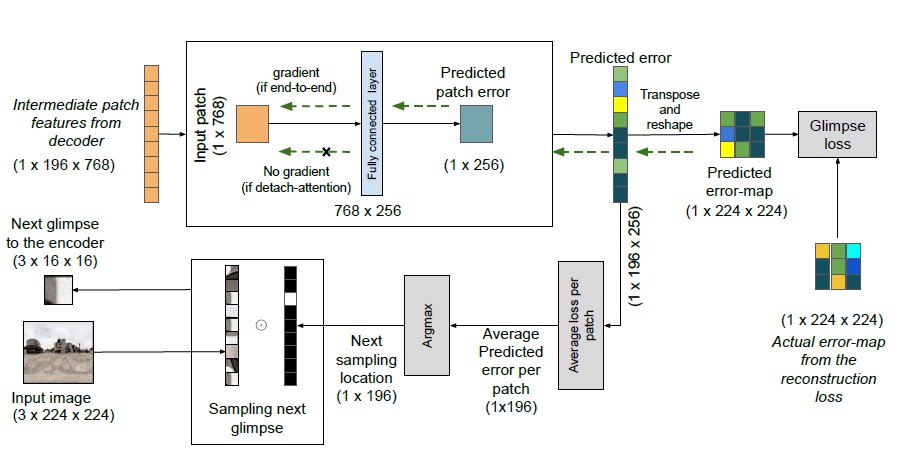 |
SimGlim: Simplified glimpse based active visual exploration Abstract
An agent with a limited field of view needs to sample the most informative local observations of an environment in order to model the global context. Current works train this selection strategy by defining a complex architecture built upon features learned through convolutional encoders. In this paper, we first discuss why vision transformers are better suited than CNNs for such an agent. Next, we propose a simple transformer based active visual sampling model, called ''SimGlim'', which utilises transformer's inherent self-attention architecture to sequentially predict the best next location based on the current observable environment. We show the efficacy of our proposed method on the task of image reconstruction in the partial observable setting and compare our model against existing state-of-the-art active visual reconstruction methods. Finally, we provide ablations for the parameters of our design choice to understand their importance in the overall architecture. |
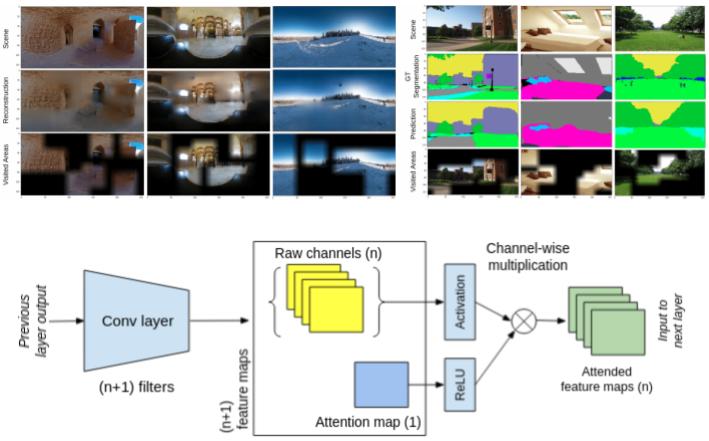 |
Glimpse attend and explore: Self-Attention for Active Visual Exploration Abstract
Active visual exploration aims to assist an agent with a limited field of view to understand its environment based on partial observations made by choosing the best viewing directions in the scene. Recent methods have tried to address this problem either by using reinforcement learning, which is difficult to train, or by uncertainty maps, which are task-specific and can only be implemented for dense prediction tasks. In this paper, we propose the Glimpse-Attend-and-Explore model which: (a) employs self-attention to guide the visual exploration instead of task-specific uncertainty maps; (b) can be used for both dense and sparse prediction tasks; and (c) uses a contrastive stream to further improve the representations learned. Unlike previous works, we show the application of our model on multiple tasks like reconstruction, segmentation and classification. Our model provides encouraging results while being less dependent on dataset bias in driving the exploration. We further perform an ablation study to investigate the features and attention learned by our model. Finally, we show that our self-attention module learns to attend different regions of the scene by minimizing the loss on the downstream task. |
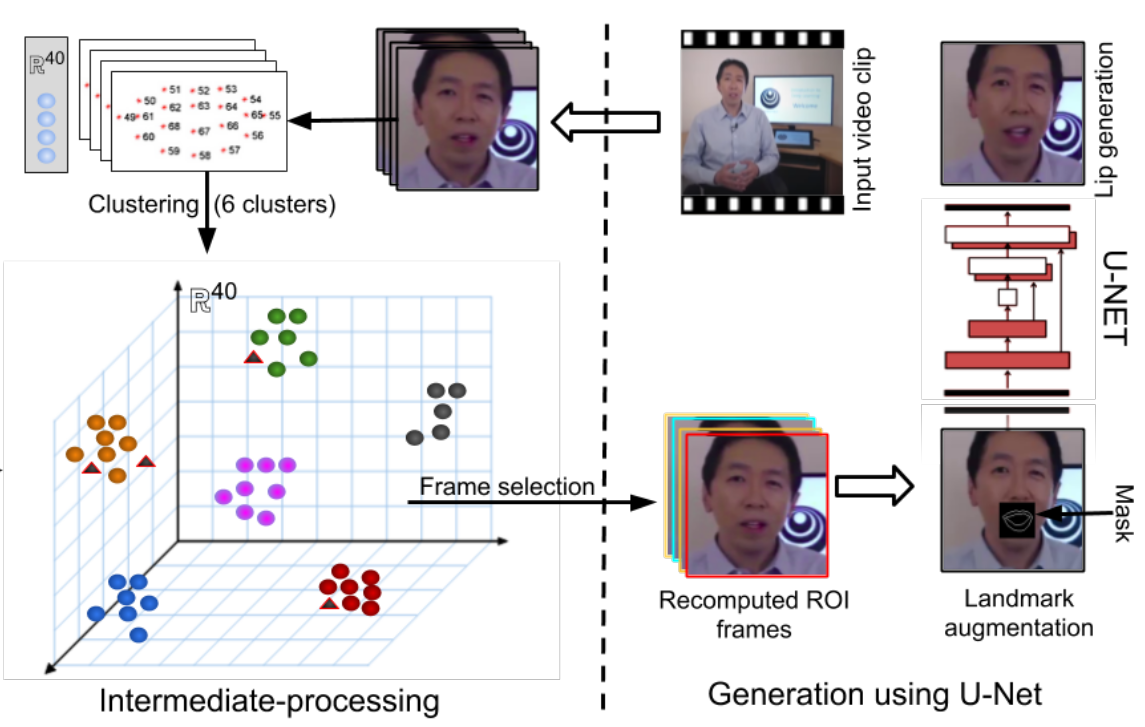 |
Cross-Language Speech Dependent Lip-Synchronization Abstract
Understanding videos of people speaking across international borders is hard as audiences from different demographies do not understand the language. Such speech videos are often supplemented with language subtitles. However, these hamper the viewing experience as the attention is shared. Simple audio dubbing in a different language makes the video appear unnatural due to unsynchronized lip motion. In this paper, we propose a system for automated cross-language lip synchronization for re-dubbed videos. Our model generates superior photorealistic lip-synchronization over original video in comparison to the current re-dubbing method. With the help of a user-based study, we verify that our method is preferred over unsynchronized videos. |
 |
Spotting Words in Silent Speech Videos : A Retrieval based approach
Abhishek Jha,
Vinay P. Namboodiri,
C. V. Jawahar |
 |
Lip-Synchronization for Dubbed Instructional Videos |
 |
Cross-modal style transfer
Abstract
We, humans, have the ability to easily imagine scenes that depict sentences such as “Today is a beautiful sunny day” or “There is a Christmas feel, in the air”. While it is hard to precisely describe what one person may imagine, the essen- tial high-level themes associated with such sentences largely remains the same. The ability to synthesize novel images that depict the feel of a sentence is very useful in a variety of appli- cations such as education, advertisement, and entertainment. While existing papers tackle this problem given a style im- age, we aim to provide a far more intuitive and easy to use solution that synthesizes novel renditions of an existing im- age, conditioned on a given sentence. We present a method for cross-modal style transfer between an English sentence and an image, to produce a new image that imbibes the essen- tial theme of the sentence. We do this by modifying the style transfer mechanism used in image style transfer to incorpo- rate a style component derived from the given sentence. We demonstrate promising results using the YFCC100m dataset. |
 |
Word Spotting in Silent Lip Videos
Abstract
Our goal is to spot words in silent speech videos without explicitly recognizing the spoken words, where the lip mo- tion of the speaker is clearly visible and audio is absent. Ex- isting work in this domain has mainly focused on recogniz- ing a fixed set of words in word-segmented lip videos, which limits the applicability of the learned model due to limited vocabulary and high dependency on the model’s recogni- tion performance. Our contribution is two-fold: 1) we develop a pipeline for recognition-free retrieval, and show its performance against recognition-based retrieval on a large-scale dataset and another set of out-of-vocabulary words. 2) We intro- duce a query expansion technique using pseudo-relevant feedback and propose a novel re-ranking method based on maximizing the correlation between spatio-temporal land- marks of the query and the top retrieval candidates. Our word spotting method achieves 35% higher mean aver- age precision over recognition-based method on large-scale LRW dataset. Finally, we demonstrate the application of the method by word spotting in a popular speech video (“ The great dictator ” by Charlie Chaplin) where we show that the word retrieval can be used to understand what was spoken perhaps in the silent movies. |
 |
Cross-specificity: modelling data semantics for cross-modal
matching and retrieval Abstract
While dealing with multi-modal data such as pairs of images and text, though individual samples may demonstrate inherent heterogeneity in their content, they are usually coupled with each other based on some higher-level concepts such as their categories. This shared information can be useful in measuring semantics of samples across modalities in a relative manner. In this paper, we investigate the problem of analysing the degree of specificity in the semantic content of a sample in one modality with respect to semantically similar samples in another modality. Samples that have high similarity with semantically similar samples from another modality are considered to be specific, while others are considered to be relatively ambiguous. To model this property, we propose a novel notion of “cross-specificity”. We present two mechanisms to measure cross-specificity: one based on human judgement and other based on an automated approach. We analyse different aspects of cross-specificity and demonstrate its utility in cross-modal retrieval task. Experiments show that though conceptually simple, it can benefit several existing cross-modal retrieval techniques and provide significant boost in their performance. |
Teaching
| Spring 2023: | Teaching assistant (TA) in the course Image Analysis and Understanding (B-KUL-H09J2A), KU Leuven. Course instructor: Prof. Tinne Tuytelaars and Dr. Marc Proesmans |
| Spring 2022: | Teaching assistant (TA) in the course Information System and Signal Processing (B-KUL-H09M0A), KU Leuven. Course instructor: Prof. Tinne Tuytelaars |
| Spring 2021: | Teaching assistant (TA) in the course Information System and Signal Processing (B-KUL-H09M0A), KU Leuven. Course instructor: Prof. Tinne Tuytelaars |
| Spring 2020: | Teaching assistant (TA) in the course Information System and Signal Processing (B-KUL-H09M0A), KU Leuven. Course instructor: Prof. Tinne Tuytelaars |
| Monsoon 2018: | Teaching assistant (TA) in the course Topics in Machine Learning (CSE975), IIIT Hyderabad. Course instructor: Prof. Naresh Manwani |
| Spring 2018: | Mentor in 1st foundations course on Artificial Intelligence and Machine Learning. Course instructor: Prof. C. V. Jawahar |